MySQL数据类型
数据类型在数据库中非常重要,对数据类型的选择将会影响数据库的性能,除此之外,在数据库中使用了不是非常合适的数据类型可能会对后期维护造成麻烦。在选择数据类型时,必须格外谨慎,因为在生产环境下更改数据库是非常危险的操作。
类型属性
有两个属性对选择数据类型有很大关系:UNSIGNED 和 ZEROFILL。
UNSIGNED 属性
UNSIGNED 属性就是将数字类型无符号化,和 C/C++ 中的 unsigned 含义相同。看起来很不错,因为很多时候对于主键是自增长类型,用户都希望主键是非负数,但在实际使用中,可能会有一些负面影响,如下:
在 MySQL 数据库中,对于 UNSIGNED 数的操作,其返回值都是 UNSIGHED 的。如果表 t 中有两个属性 a 为 1,b 为 2 都是UNSIGNED 的,那么:
| |
的结果是什么?
在 Mac 上会报错:BITINT UNSIGNED 超出范围,在 Linux 上得到结果为 4294967295。这并不是 MySQL 的 bug,而是在 C 语言中同样会出现这样的问题:
| |
0xFFFFFFFF 就是无符号整型的最大值,但对于有符号整型来说,第一位代表符号,如果为 1,就是负数,取反 +1 就得到了负数值 -1。这也是计算机组成原理方面的知识。
怎么获取 -1 这个值?只要对 SQL_MODE 这个参数进行设置即可。即:
| |
尽量不要使用 UNSIGNED,因为可能会带来意想不到的效果,同时对于 INT 存放不了的结果,UNSIGNED 也存放不了,还不如在设计阶段就将数据类型提升为 BIGINT 类型。
ZEROFILL 属性
ZEROFILL 更像是一个显示属性,初学者对数据库中数字类型后面的长度值很迷茫,可以通过如下建表语句:
| |
上面的 int(10) 代表什么,整型不是只有 4 个字节吗?其实如果没有 ZEROFILL 这个属性,括号内的数字毫无意义。如果插入 a:1,b:2。但是在对列添加 ZEROFILL 属性后,显示结果就有所不同了,例如如下修改:
| |
对 a 列进行了修改,为其添加了 ZEROFILL 属性,并且将默认的 int(10) 修改为了 int(4),设置查找操作,返回结果如下:
| |
这就是 ZEROFILL 属性的作用,如果宽度小于设定的宽度,自行填充 0。但这只是显示的效果,实际存储还是 1,可以用函数 HEX 证明:
| |
可以看到在数据库内部存储的还是 1,0001 只是设置了 ZEROFILL 属性后的一种格式化输出而已。如果真存 0001 那么加减乘除该怎么操作呢?
SQL_MODE 设置
SQL_MODE 可能是比较容易让开发人员忽视的一个变量,默认为空。SQL_MODE 是一种比较冒险的设置,因此这种设置下可以允许一些非法操作,比如将 NULL 插入 NOT NULL 的字段中,也可以插入一些非法日期,如“2012-12-32”。因此在开发环境中需要将这个值设置为严格模式,这样在出现问题时候,就可以在开发阶段发现,如果在生产环境下,发现这类问题,代价将非常大。
SQL_MODE 的设置可以在 my.cnf 和 my.ini 中进行,也可以在客户端工具中新型,并且可以分别进行全局的设置或当前会话的设置,下面的命令可以用来查看当前 SQL_MODE 的设置情况。
| |
可以看到此 MySQL 当前全局的 SQL_MODE 设置为空,而当前会话的设置为 NO_UNSIGNED_SUBTRACTION。通过以下语句可以将当前的 SQL_MODE 设置为严格模式:
| |
SQL_MODE 可以设置的选项如下:
| 选项 | 描述 |
|---|---|
| STRICT_TRANS_TABLES | 在该模式下,如果一个值不能插入到一个事务表中,中断当前操作不影响非事务表。 |
| ALLOW_INVALID_DATES | 不完全对日期的合法性进行检查,只检查月份是 1~12,日期是 1~31 之间。仅对 DATA 和 DATATIME 类型有效。而对 TIMESTAMP 无效。 |
| ANSI_QUOTES | 启用 ANSI_QUOTES 后,不能用双引号来引用字符串,因为它被解释为识别符。 |
| ERROR_FOR_DIVISION_BY_ZERO | 在 INSERT 或 UPDATE 过程中,如果数据被 0 除或 mode 0,则产生错误,如果未给出该模式,数据被零除返回 NULL。 |
| HIGH_NOT_PERCEDENCE NOT | 操作符的优先顺序是表达式,例如 NOT a BETWEEN b AND c,被解释为 NOT (a BETWEEN b AND c)。 |
| IGNORE_SPACE | 函数名和括号“(”之间有空格。除了增加一些烦恼,这个选项没有任何好处。 |
| NO_AUTO_CREATE_USER | 禁止 GRANT 创建密码为空的用户。 |
| NO_AUTO_VALUE_NO_ZERO | 该选项影响列为自增长的插入。默认设置下,插入 0 代表生成下一个自增长值,如果用户希望插入的值为 0,而该列又是自增长的,这个选项就有用了。 |
| NO_BACKSLASH_ESCAPES | 反斜杠“\”作为普通字符而非转义符。 |
| NO_DIR_IN_CREATE | 在创建表时忽视所有 INDEX DIRECTORY 和 DATA DIRECTORY 选项。 |
| NO_ENGINE_SUBSTITUTION | 如果需要的存储引擎被禁用或未编译,那么抛出错误。 |
| NO_UNSIGNED_SUBTRACTION | 启用这个后两个 UNSIGNED 类型相减返回 SIGNED 类型。 |
| NO_ZERO_DATA | 在非严格模式下,可以插入“0000-00-00”的非法日期,MySQL 仅抛出错误而非警告。 |
| NO_ZERO_IN_DATA | 在严格模式下,不允许日期和月份为零。如“2011-00-01”这样格式不允许。 |
| ONLY_FULL_GROUP_BY | 对于 GROUP BY 聚合操作,如果在 SELECT 中的列没有在 group by 中出现,那么语句不合法。 |
| PAD_CHAR_TO_FULL_LENGTH | 对于 CHAR 类型字段,不要节段空洞数据。也就是自动填充值为 0x20的数据,默认情况下,如果 a CHAR(10),使用 CHAR_LENGTH(a),MySQL 返回长度为 1,hex(a): 61。启用该选项后,长度为 10,hex(a):61202020202020…。 |
| PIPES_AS_CONCAT | 将 | 视为字符串的连接操作符而非或运算符。 |
| REAL_AS_FLOAT | 将 REAL 视为 FLOAT 的同义词,而不是 DOUBLE 的同义词。 |
| STRICT_ALL_TABLES | 对所有引擎的表都启用严格模式。严格模式下,一旦任何操作的数据产生问题,都会终止当前的操作。 |
还有些其他的组合操作:ANCI、ORACLE、TRADITIONAL、MSSQL、DB2等不详细赘述。
数字类型
整形
MySQL 数据库支持 SQL 标准支持的整型类型:INT、SMALLINT。此外还支持 TINYINT、MEDIUMINT、BIGINT 等类型。
范围如下:
| 类型 | 占用字节 | 最小值(SIGNED/UNSIGNED) | 最大值(SIGNED/UNSIGNED) |
|---|---|---|---|
| TINYINT | 1 | -128 / 0 | 127 / 255 |
| SMALLINT | 2 | -32768 / 0 | 32767 / 65535 |
| MEDIUMINT | 3 | -8388608 / 0 | 8388607 / 16777215 |
| INT | 4 | -2147483648 / 0 | 2147483647/ 4294967295 |
| BIGINT | 8 | -9223372036854775808 / 0 | -9223372036854775807 / 18446744073709551615 |
一旦启用了 ZEROFILL 属性,MySQL 数据库为列自动添加 UNSIGNED 属性。
浮点型
MySQL 支持两种浮点型数据:FLOAT(单精度)和 DOUBLE PRECISION(双精度)类型。这两种类型都是非精确类型,经过一些操作后并不能保证运算的精准型。
SQL 标准允许在关键字 FLOAT 后面的括号中用位来指定精度。MySQL 还支持可选的只用于确定存储大小的精度规定,0~23 位精度对应 FLOAT 列的 4 字节单精度,24~53的精度对应 DOUBLE 列的 8 字节双精度。
但 MySQL 允许使用非标准语法:FLOAT(M, D) 或 REAL(M, D) 或 DOUBLE PRECISION(M, D)。其中 M 表示该值一共显示 M 位整数,其中 D 位时小数点后面的位数。例如:FLOAT(7, 4) 的一个列可以显示为 -999.9999。MySQL 在保存值的时候会进行四舍五入,因此在 FLOAT(7, 4) 列内插入 999.00009 的近似结果是 999.0001。
MySQL 将 DOUBLE 和 REAL 视为 DOUBLE PRECISION 的同义词。但如果将 MySQL 服务器的模式设置为 REAL_AS_FLOAT,这时 REAL 将被视为 FLOAT 类型。
为了保证最大可以执行,最好使用 FLOAT 或 DOUBLE PRECISION,并不规定精度或位数。
高精度类型
除此之外:DECIMAL 和 NUMERIC 类型在 MySQL 中被视为相同的类型,用于保存必须为确切精度的值。在计算工资时,可以指定精度和标度,例如:salary DECIMAL(5, 2)。其中,5 是精度,2 是标度。精度表示保存值的主要位数,标度表示小数点后面可以保存的位数。DECIMAL(M) 等价于 DECIMAL(M, 0)。在 MySQL 中 M 的值默认为 10。DECIMAL 或 NUMERIC 的最大位数为 65,如果值的小数点后位数超过指定的标度允许的范围,值将按该标度进行转换。
位类型
即 BIT 数据类型可以用来保存字段的值。BIT(M) 类型表示允许存储 M 位数值,M 范围为 1 到 64,占用的空间为 (M+7)/8 字节。如果为 BIT(M) 列分配的的长度消息 M 位,在值的左边用 0 填充。例如 BIT(6) 列分配一个值位 b'101’ 和分配 b'000101’相同,要指定位值,可以使用 b’value’ 符,例如:
| |
字符类型
字符集
在字符类型前,先说一下字符集。很多问题因为开发人员忽视了字符集问题,导致后期维护成本很高。在 MySQL 中,默认的字符集为 lantin1,对于以英文为母语的国家应用 MySQL 来说,这个字符集并不会带来什么问题,但是对于中文字符集,这可能会是一个灾难。
通过 SHOW CHARSET 可以查看 MySQL 数据库支持的字符集。MySQL 字符集有很多种,如下图:
对于简体中文,我们常常使用的是 gbk 或 gb2312,gdb 是 gb2313 的超集,因此可以支持更多汉字。对于繁体中文,首选的字符集为 big5。
而如果存储的字符是多种多样的,有必要将字符集设置成 Unicode 编码,比如一些游戏如果要输出到其他国家。
此外,Unicode 和 UTF-8 并不是等价的,两者还是存在很大的区别。Unicode 是一种在计算机上使用的字符编码。为每种语言的字符设定了统一的二进制编码,以满足跨语言和跨平台文本转换和处理的要求。
Unicode 是国际组织制定的可以容纳世界上所有文字和符号的字符编码方案。Unicode 使用数字 0~0x10FFFF来映射这些字符,最多可以容纳 114112 个字符,或者说是码位(码位就是可以分配给字符的数字)。UTF-8、UTF-16、UTF-12 都是将数字转换到程序的编码方案。
可以通过 SQL 语句来查村 MySQL 支持的 Unicode 编码的字符集。
| |
MySQL 5.5 支持 ucs2、utf8(utf8mb3)、utf8mb4、utf16、以及 utf32 五种 Unicode 编码。utf-8 目前被视为 utf8mb3,也就是最大占用 3 个字节,而 utf8mb4 作为 utf8mb3 的拓展。对于 Basic Multilinggual Plane 字符的存储,utf8mb3 和 utf8mb4 两者是完全一样的,区别是 utf8mb4 对拓展字符的支持。
对于 Unicode 编码的字符集,强烈建议将所有的 CHAR 字段设置为 VARCHAR 字段,因为对于 CHAR 字段,数据库会保存最大可能的字节数。例如 CHAR(30),数据库可能存储 90 个字节的数据。
字符集的设置可以在 MySQL 的配置中完成,例如:
| |
如果要查看当前使用的字符集,可以使用 STATUS 命令:
| |
命令 SET NAMES 可以用来更改当前会话连接的字符集、当前会话的客户端的字符集,以及当前会话返回结果集的字符集,如:
| |
MySQL 数据库还有一个比较强悍的地方是,可以细化每个对象字符集的设置:
| |
如果定义表时没有给出具体字符集,则采用创建架构(Schema)时指定的字符集。如果没有在创建架构时指定字符集,则使用数据配置文件中指定的字符集。
SQL 标准支持 NCHAR 类型(National Character Set),在 MySQL 5.5 数据库中使用 utf8 来表示这种类型。例如:
| |
上面创建表时将 a 列定义为 NCHAR(10),但是在创建数据库过程中,实际使用的时 utf8 字符集。
排序规则
排序规则是指对指定字符集下不同字符的比较规则。有以下特征:
- 不同的字符集不能有相同的排序规则。
- 每个字符集有一个默认的排序规则。
- 有一些常用的命名规则。如 ci 表示大小写不敏感(case insensitive), cs 表示大小写敏感(case sensitive),_bin 表示二进制的比较(binary)。
MySQL 中可以通过命令 SHOW COLLATION 查看支持的各种排序规则:
| |
也可以通过 information_schema 架构下的表 COLLATIONS 来查看。
可以看到,对于 gbk 字符集,有两种排序规则,分别是 gdk_chinese_ci 和 gdb_bin。前面介绍的命令 SHOW CHARSET 已经显示了每种字符集的默认排序规则,如果用户需要查看 gdk 字符集,可以使用命令:
| |
排序规则有什么用呢,下面将详细介绍:
| |
执行 SQL 查询语句的时候可能只是搜索小写字符 a,但是 A 也返回到结果集中。这个问题是因为 utf8 字符集默认的排序规则是 utf8_general_ci。之前介绍过 _ci 结尾表示大小写不敏感,所以 a 和 A 被视为一致的字符返回了。也可以直接对这两个字符进行比较:
| |
可以看到返回值为 1,即两个字符相等。
如果我们需要更改当前会话的排序规则,可以通过命令 SET NAMES… COLLATE… 来实现,例如:
| |
可以看到这时数据库会认为 a 和 A 是不同的字符。对于创建的表 t 如果需要对 a 列区分大小字符,则可以将 a 列的排序规则修改为 utf8_bin,例如:
| |
是否要设置大小写敏感,需要根据程序的需求而定,并不是总要求区分大小写字符。比如:用户注册表如果希望用户再注册时不要区分大小写。另外排序规则不仅影响大小写的比较,还影响着索引。例如:我们将表 t 的 a 列修改为之前的定义,然后再创建一个 a 列上的唯一索引。
| |
可以看到,a 列不区分大小写后,就不能再 a 列上创建一个唯一索引,提示有重复数据。索引是 B+ 树,同样需要对字符进行比较,因此再建立唯一索引时,由于排序规则对大小写不敏感而导致了错误。
再 MySQL 数据库中还有一种被称为 binary 的排序规则,其和 _bin 的排序规则大致相同。
CHAR和VARCHAR
CHAR 和 VARCHAR 是最常用的两种字符串类型。
CHAR(N):用来保存固定长度的字符串,N 的范围为 0~255。
VARCHAR(N):用来保存变长字符类型,N 的范围为 0~65525。
CHAR(N) 和 VARCHAR(N) 中的 N 都代表字符长度,而非字节长度(但在老版本中 N 代表的是字节长度)。
对于 CHAR 类型的字符串,MySQL 数据库会自动对存储列的右边进行填充操作,直到字符串达到指定长度 N。
而在读取该列时,MySQL 数据库会自动将填充的字符删除。另外一种情况,就是显示的将 SQL_MODE 设置为 PAD_CHAR_TO_FULL_LENGTH,例如:
| |
LENGTH 函数返回的是字节长度而非字符长度。
对于多结字字符集,CHAR(N) 长度的列最多可占用 30 个字节。通过对多字节字符串使用 CHAR_LENGTH 函数 和 LENGTH 函数,可以发现两者的不同,示例如下:
| |
因为中文 gdk 字符集的中文字符占用两个字节,因此一共占用 13 字节,而字符串的长度为 9。
VARCHAR 类型存储变长字段的字符类型,与 CHAR 类型不同的是,其存储时需要在前缀列表加上实际存储的字符,该字符占用 1~2 字节空间。当存储的字符串长度小于 255 字节时,需要 1 字节空间,当大于 255 字节时,需要 2 字节空间。如果数据的实际长度比设定长度短,那么它将按照实际长度储存,而不占用剩余的空间。
所以,对于单字节的 lantin1 来说,CHAR(10) 和 VARCHAR(10) 最大占用的存储空间是不同的,CHAR(10) 占用 10 字节,而 VARCHAR(10) 占用 11 字节。
虽然 char 和 varchar 存储方式不太相同,但是对于两个字符串的比较,都是比较其值,忽略 CHAR 值存在的填充,即使将 SQL_MODE 设置为 PAD_CHAR_TO_FULL_LENGTH 也一样。
| |
BINARY 和 VARBINARY
BINARY 和 VARBINARY 与前面介绍的 CHAR 和 VARCHAR 类型有点类似,但是 BINARY 和 VARBINARY 存储的是二进制的字符串, 没有任何字符集的概念,而且对其排序和比较都是按照二进制进行对比的。
无论实际存储的数据有多少,BINARY 类型都会占用n个字节的存储空间。如果插入的数据长度小于n,SQL Server会在数据的右侧用0x00(即二进制的0)进行填充,以达到指定的长度。
与 BINARY 不同,VARBINARY 只占用实际数据的长度加上额外的2到4个字节(用于存储数据的长度信息)的存储空间。如果指定了max,则最大可以存储2^31-1个字节的数据,即最大4GB。
BINARY(N) 和 VARBINARY(N) 中的 N 指的是字节长度,并不是 CHAR(N) 和 VARCHAR(N) 中的字符长度。比如 BINARY(10) 表示存储的字节固定为 10,但对于 CHAR(10) 其存储的字节和字符集的情况而定。
比如:
| |
因为 gdk 字符集中“我”占用两个字节,所以在插入时会有警告,提示字符被截断。如果 SQL_MODE 设置为严格模式,将直接报错。在插入后,直插入了“我”的前一个字节,后一个 字符被截断了。如果改为 CHAR 类型,将完全不会出现上述的问题。
所以 BINARY 和 VARBINARY 与 CHAR 和 VARCHAR 的最主要的区别是:
- BINARY(N) 和 VARCHAR(N) 中的 N 代表的是数字,并不是字符长度。
- CHAR 和 VARCHAR 在进行字符比较时,比较的只是字符本身的存储,忽略字符后的填充字符。而 BINARY 和 VARBINARY 是直接按照二进制进行对比。
- 对于 BINARY 字符串,填充值是 0x00,而 CHAR 的填充字符为 0x20。可能是因为 BINARY 的比较需要,0x00 是比较的最小字符。
BLOB 和 TEXT
BLOB (Binary Large Object) 用来存储二进制大数据的类型。而且根据长度不同,BLOB 可以细分为以下 4 中类型,括号中表示存储的字节数:
TINYBLOB (2^8) = 256 字节
BLOB (2^16) = 65536 字节 = 64 KB
MEDIUMBLOB (2^24) = 16777216 字节 = 16384 KB = 16 MB
LONGBLOB (2^32) = 4294967296 字节 = 4194394 KB = 4096 MB = 1GB
同样 TEXT 类型同 BLOB 一样,可以细分为 4 种:
TINYTEXT (2^8) = 256 字节
TEXT (2^16) = 65536 字节 = 64 KB
MEDIUMTEXT (2^24) = 16777216 字节 = 16384 KB = 16 MB
LONGTEXT (2^32) = 4294967296 字节 = 4194394 KB = 4096 MB = 1GB
多数情况下,可以将 BLOB 类型视为足够大的 VARBINARY 类型的列,TEXT 也可以视为足够大的 VARCHAR 类型的列。
但是 BLOB 和 TEXT 在以下几个方面不同于 VARBINARY 和 VARCHAR:
- 在 BLOB 和 TEXT 类型的列上创建索引时,必须指定索引前缀的长度。但 VARCHAR 和 VARBINARY 的前缀长度是可选的。
- BLOB 和 TEXT 类型的列不能有默认值。
- 在排列时只使用列的前 max_sort_length 个字节。
max_sort_length 默认值是 1024,该参数为动态参数,任何客户端都可以在 MySQL 数据库运行时更改该参数的值。例如:
| |
数据库中最小的存储单元是页(也成为块),为了有效存储 BLOB 类型或 TEXT 大数据类型,一般将 BLOB 列的具体数据存放在行溢出页,而数据页存储的行数据只包含 BLOB 或 TEXT 类型数据列前一部分数据。这种方式使得页中能存放大量的行数据,从而提高了数据的查询效率。 有点类似于 C 语言中的指针,列中存储的只是指针变量,而实际的数据则在指针所指向的实际地址。 如下图所示:
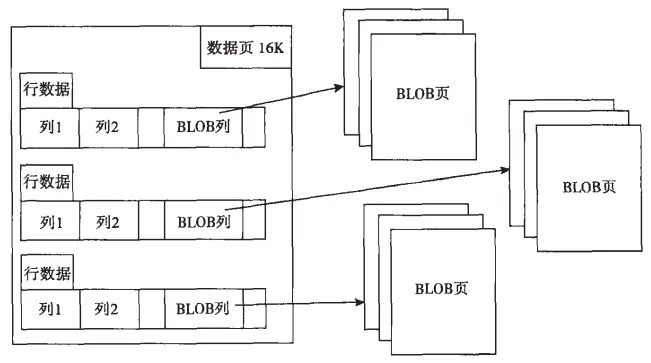
此外,有些存储引擎中,比如 InnoDB 存储引擎,会将大的 VARCHAR 类型字符串(VARCHAR(65530))自动转换为 TEXT 或 BLOB 类型。
ENUM 和 SET
ENUM 和 SET 类型都是集合类型,不同的是 ENUM 类型最多可以枚举 65525 个元素,二 SET 只能枚举 64 个元素。
由于 MySQL 不支持传统的 CHECK 约束,因此通过 ENUM 和 SET 类型并结合 SQL_MODE 可以解决一部分问题。例如:表中有一个“性别”列,规定范围只能是 male 和 female,这种情况下可通过严格的 SQL_MODE 模式进行约束,如下:
| |
日期和时间类型
MySQL 中有物种与日期和时间有关的数据类型,各种日期数据类型所占空间如下:
DATETIME 8 字节
DATE 3 字节
TIMESTAMP 4 字节
YEAR 1 字节
TIME 3 字节
DATETIME 和 DATE
DATETIME 是占用空间最多的一种类型,即显示了日期,同时也显示了时间。表达的日期范围为“1000-01-01 00:00:00”到“9999-12-31 23:59:59”。
DATE 占用 3 字节,可显示的日期范围为“1000-01-01”到“9999-12-31”。
在 MySQL 中,对日期的和时间输入格式的要求是非常宽松的,比如下面的输入都可以视为日期类型。
2011-01-01 00:01:10
2011/01/01 00+01+10
20110101000110
11/01/01 00@01@01 注:这种将其视为离现在最近的一个年份,不是好的习惯。
如果没有特别的条件和要求,按照标准的“YYYY-MM-DD HH:MM:SS”格式进行。
在MySQL 5.5 之前,数据库的日期类型都不能精确到微秒级别,任何微秒数值都会被数据库截断,如:
| |
虽然也有一些函数可以用来显示微秒值:
| |
CAST 函数在强制转换到 DATETIME 时会保留到微秒数,不过在插入后依旧会被截断,如下:
| |
从 MySQL 5.6.4 版本,MySQL 增加了对秒的小数部分的支持,语法为:
| |
type_name 类型可以是 TIME、DATETIME、TIMESTAMP。fsp 表示支持秒的小鼠部分的精度,最大为 6,表示微秒,默认为 0,表示没有小数部分,同时也是为了兼容之前版本中的 TIME、DATETIME 和 TIMESTAMP 类型。对于时间函数,如 CURTIME()、SYSDATE()、UTC_TIMESTAMPP() 也增加了对 fsp 的支持,例如:
| |
TIMESTAMP
TIMESTAMP 和 DATETIME 显示的结果是一样的,都是固定的“YYYY-MM-DD HH:MM:SS”,但是 TIMESTAMP 只占用 4 字节,而且表示的时间范围也只有“1970-01-01 00:00:00”到“2038-01-19 03:14:07”,但实际存储的是当前时间的毫秒数。这一点和 Linux 中时间戳对应的。
除了时间范围上不同,还有以下区别:
- 建表时,列为 TIMESTAMP 类型可以设置一个默认值,而 DATETIME 不行。
- 更新表时,可以设置 TIMESTAMP 类型的列自动更新时间为当前时间。
如下实例:
| |
可以发现在执行 UPDATE 操作后,b 列的时间由原来的 16:45:40 更新为 16:47:39。
如果执行了上面的 UPDATE 操作,但并没有改变 a 本来的值,那么也不会更新 b 列的值。
| |
YEAR 和 TIME
YEAR 类型占用 1 字节,并且可以在定义时指定显示的宽度为 YEAR(4) 和 YEAR(2),例如:
| |
对于 YEAR(4),其显示年份范围为 1901~2155;对于 YEAR(2),其显示年份的范围为 1970~2070。在 YEAR(2) 的是遏制,00~69 代表 2000~2069 年。
TIME 类型占用 3 字节,显示的范围为“-839:59:59”到“838:59:59”,为什么 TIME 时间可以大于 23,因为 TIME 类型不仅可以用来保存这一天中的时间,也可以用来保存时间间隔,这就是为什么 TIME 类型可以为负数。和 DATATIME 类型一样,TIME 类型同样可以显示微秒时间,但是在插入时,数据库同样会进行截断操作,例如:
| |
与日期和时间相关的函数
日期函数可能是比较常用的一种函数。
NOW、CURRENT_TIMESTAMP 和 SYSDATE
这些函数都能返回系统当前的时间,但是有一定区别:
| |
可以看到 SYSDATE 返回的时间慢了 2 秒。这三个函数有略微区别:
CURTIME_TIMESTAMP 是 NOW 的同义词,也就是说两者是相同的。
SYSDATE 函数返回的是执行到当前函数时的时间,而 NOW 返回的是执行 SQL 语句时的时间。
因此在上面的例子中,两次执行 SYSDATE 函数返回不同的的时间是因为第二次调用之前 SLEEP 了 2 秒。而对于 NOW 函数,不论在 SLEEP 函数之前还是之后,返回都是执行这条 SQL 语句时间。
时间加减函数
想要对当前时间进行增加或减少,并不能直接加或减一个数字,而需要使用特定的函数,如 DATE_ADD 或 DATA_SUB,前者表示增加,后者表示减少。具体的使用方法有:
DATE_ADD(date, INTERVAL expr unit) 和 DATE_SUB(date, INTERVAL expr unit),实例如下:
| |
其中 expr 值可以是正值,也可以是负值,因此可以使用 DATE_ADD 函数完成 DATE_SUB 函数的工作例如:
| |
怎么处理闰月?MySQL 默认如果目标年份时闰月,那么 2 月就有 29 号,否则 2 月就只有 28 号。
| |
上面使用了 DAY 和 YEAR 数据类型,其实也可以使用 MICROSECOND、SECOND、MINUTE、HOUR、WEEK、MONTH 等类型,例如:
| |
DATE_FROMAT 函数
这个函数是按照用户的需求格式化打印出日期
| |
但是可能会误用这个函数,导致严重后果:
| |
一般情况,表中都会对一个日期类型索引,如果使用上述语句,优化器将不会使用索引,也不可能通过索引来查询数据,因此上述查询的执行效率可能非常低。
| 格式 | 描述 |
|---|---|
| %a | 缩写星期名 |
| %b | 缩写月名 |
| %c | 月,数值 |
| %D | 带有英文前缀的月中的天 |
| %d | 月的天,数值(00-31) |
| %e | 月的天,数值(0-31) |
| %f | 微秒 |
| %H | 小时 (00-23) |
| %h | 小时 (01-12) |
| %I | 小时 (01-12) |
| %i | 分钟,数值(00-59) |
| %j | 年的天 (001-366) |
| %k | 小时 (0-23) |
| %l | 小时 (1-12) |
| %M | 月名 |
| %m | 月,数值(00-12) |
| %p | AM 或 PM |
| %r | 时间,12-小时(hh:mm:ss AM 或 PM) |
| %S | 秒(00-59) |
| %s | 秒(00-59) |
| %T | 时间, 24-小时 (hh:mm:ss) |
| %U | 周 (00-53) 星期日是一周的第一天 |
| %u | 周 (00-53) 星期一是一周的第一天 |
| %V | 周 (01-53) 星期日是一周的第一天,与 %X 使用 |
| %v | 周 (01-53) 星期一是一周的第一天,与 %x 使用 |
| %W | 星期名 |
| %w | 周的天 (0=星期日, 6=星期六) |
| %X | 年,其中的星期日是周的第一天,4 位,与 %V 使用 |
| %x | 年,其中的星期一是周的第一天,4 位,与 %v 使用 |
| %Y | 年,4 位 |
| %y | 年,2 位 |
 支付宝
支付宝 微信
微信